

How Does the Genetic Code Work in Living Organisms?
The genetic code definition revolves around how information stored in DNA is translated into proteins. Each protein in a living organism is synthesised according to specific instructions encoded in DNA and relayed via mRNA. When we talk about the characteristics of genetic code, we mean the features that govern how nucleotide triplets (codons) determine which amino acids are assembled to form proteins. This guide will walk you through every crucial detail—from how the code is read, to an engaging genetic code example, and even a glimpse into DNA fingerprinting. By the end, you’ll see why scientists say the genetic code is degenerate yet remarkably precise, and how it acts as life’s universal language.
What is the Genetic Code?
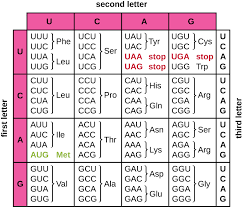
When we discuss the genetic code definition, we refer to a set of rules by which cells translate the sequence of nucleotides in DNA or mRNA into a sequence of amino acids in a protein. This translation is performed by ribosomes with the help of tRNA (transfer RNA). Each codon—made up of three nucleotides—represents one amino acid (or a start/stop signal). Although this might sound straightforward, the code has evolved to include interesting twists, exceptions, and redundancies that ensure organisms can efficiently create the proteins they need.
Discovery and Significance
Biologists Marshall Nirenberg, Har Gobind Khorana, and others were pioneers in cracking the genetic code. Their discoveries allowed us to map each triplet codon to its corresponding amino acid. This revolutionary insight helps modern science in gene therapy, CRISPR gene editing, and even DNA fingerprinting, which identifies unique genetic patterns in individuals.
Characteristics of Genetic Code
The characteristics of genetic code help clarify how proteins are accurately synthesised:
Triplet Code
Each codon is a set of three nucleotides (e.g., AUG, GCU), and each three-letter codon specifies one amino acid or a termination signal.
Commaless Code
Codons are read in sequence without any punctuation. For instance, a continuous chain like 5’-AUGCCUGAA-3’ is segmented into (5’-AUG-3’) – (5’-CCU-3’) – (5’-GAA-3’).
Non-overlapping Code
Once a codon is read, its nucleotides cannot be part of another codon. After 5’-AUG-3’ is read, the next codon starts immediately at the following nucleotide.
Polarity
Codons are read from the 5’ to 3’ direction. Reversing the codon order (3’ to 5’) would encode entirely different amino acids, emphasising the directionality in protein synthesis.
Genetic Code is Degenerate
Each amino acid, except methionine (AUG) and tryptophan (UGG), can be encoded by multiple codons. This redundancy is why we say the genetic code is degenerate. For example, leucine can be specified by six different codons.
Start and Stop Codons
Start Codon: AUG, signalling where translation begins. In eukaryotes, AUG codes for methionine. In prokaryotes, it can code for a modified form of methionine (N-formylmethionine).
Stop Codons: UAA, UAG, and UGA. These do not code for any amino acid and signal the ribosome to terminate protein synthesis.
Non-ambiguous and Universal
A given codon always specifies the same amino acid across almost all forms of life, underscoring the universal nature of the code. However, minor exceptions exist in some mitochondrial or microbial codes.
Exceptions to the Code
Certain organisms or mitochondria use alternative start or stop signals. Occasionally, GUG can act as a start codon (normally it encodes valine), illustrating rare deviations from the standard rules.
Genetic Code Example
A common genetic code example is how the codon AUG serves dual roles:
It codes for methionine in eukaryotes.
It often acts as the start signal for protein synthesis.
Another genetic code example is UAA, UAG, and UGA—these are stop codons that do not add an amino acid but terminate translation. Showcasing these examples highlights why the genetic code definition remains a cornerstone in understanding modern genetics.
Role of the Genetic Code in DNA Fingerprinting
While dna fingerprinting is largely about identifying unique patterns in an individual's DNA rather than translating codons, an understanding of the genetic code streamlines how researchers locate specific genes and mutations. DNA fingerprinting often uses repetitive DNA sequences known as VNTRs (Variable Number of Tandem Repeats) or STRs (Short Tandem Repeats), but advanced identification techniques still rely on knowledge of the genetic code definition to pinpoint specific genetic markers. Whether in forensic labs or ancestry tests, DNA fingerprinting leverages genetic variations among individuals to generate a "fingerprint" that is virtually unique.
Also, read DNA Replication
Key Points to Remember
Synthetic Biology Applications: Researchers use the standard genetic code to engineer novel pathways in microorganisms, producing drugs, biofuels, or novel biomaterials.
Personalised Medicine: By understanding how the genetic code is degenerates, personalised treatments can be developed to manage diseases linked to codon mutations.
Evolutionary Perspective: The near-universal nature of the genetic code suggests a common evolutionary origin. Studying exceptions can hint at how early life on Earth adapted to diverse environments.
Quick Quiz: Test Your Understanding
Which codon is typically recognised as the start codon?
Why do we say the genetic code is degenerate?
Name the three stop codons.
Which direction is the genetic code read in: 5’→3’ or 3’→5’?
Give a genetic code example of a codon specifying leucine.
Check Your Answers Below:
AUG
Because most amino acids (except methionine and tryptophan) have multiple codons.
UAG, UAA, and UGA
5’→3’ direction
CUU, CUC, CUA, CUG, UUA, or UUG (all valid codons for leucine)


FAQs on Genetic Code Explained: Meaning, Characteristics & Importance
1. What is the genetic code, as per the CBSE Class 12 syllabus?
The genetic code is the set of rules by which genetic information encoded within DNA or mRNA sequences is translated into the sequence of amino acids in a protein. It acts as a biological dictionary, where three-letter nucleotide words, called codons, specify which amino acid should be added to a growing polypeptide chain during protein synthesis, as per the CBSE 2025-26 curriculum.
2. What are the key properties or characteristics of the genetic code?
The genetic code has several key characteristics that are fundamental to its function:
- Triplet Nature: Each codon consists of three nucleotides.
- Degeneracy: An amino acid can be coded by more than one codon.
- Non-overlapping & Commaless: The code is read continuously, three nucleotides at a time, without any punctuation or overlap between codons.
- Universality: The same codons specify the same amino acids in almost all organisms, from bacteria to humans.
- Non-ambiguous: One specific codon will always code for the same single amino acid.
- Start and Stop Signals: It includes specific codons (like AUG) to initiate translation and others (UAA, UAG, UGA) to terminate it.
3. How many codons are there in total, and what do they code for?
In total, there are 64 possible codons (since there are 4 different bases and they are read in triplets, 4³ = 64). Out of these, 61 codons specify one of the 20 amino acids. The remaining 3 codons (UAA, UAG, and UGA) act as stop signals or termination codons, which do not code for any amino acid and signal the end of protein synthesis.
4. What are the specific start and stop codons in mRNA?
The primary start codon is AUG, which signals the beginning of translation and also codes for the amino acid methionine. The three stop codons, also known as nonsense codons, are UAA (ochre), UAG (amber), and UGA (opal). These codons signal the ribosome to terminate the process of protein synthesis.
5. Why is the genetic code described as 'degenerate' but not 'ambiguous'?
This is a key distinction. The code is 'degenerate' because a single amino acid can be specified by multiple different codons. For example, the amino acid Leucine is coded by six different codons (e.g., CUU, CUC, CUA). However, the code is 'non-ambiguous' because a single, specific codon will always code for only one specific amino acid. For instance, the codon CUU will only ever code for Leucine, never for another amino acid. This redundancy provides a buffer against mutations without creating confusion during translation.
6. What is the real-world importance of the genetic code being nearly universal?
The near-universality of the genetic code is powerful evidence for a common evolutionary ancestry among all life on Earth. Its practical importance is enormous in biotechnology and genetic engineering. Because the code is universal, a human gene, like the one for insulin, can be inserted into a bacterium, and the bacterium's cellular machinery will correctly read the codons and produce functional human insulin.
7. How do frameshift mutations highlight the importance of the code being commaless and non-overlapping?
The genetic code is read in a continuous, fixed frame (three bases at a time) without punctuation. A frameshift mutation, which involves the insertion or deletion of one or two nucleotides, shifts this entire reading frame. This demonstrates the code's commaless nature because a single change scrambles every downstream codon, leading to a completely different and usually non-functional protein. This confirms that the cellular machinery reads the code in a strict, sequential, non-overlapping manner.
8. Can you provide an example of an exception to the universal genetic code?
Yes, while the code is nearly universal, minor exceptions exist. A common example is found in mitochondrial DNA. In human mitochondria, the codon UGA, which is normally a stop codon in the nucleus, codes for the amino acid tryptophan. Similarly, AGA and AGG, which code for arginine in the standard code, act as stop codons in mitochondria. These exceptions highlight that the code has undergone minor evolutionary changes in specific organelles or organisms.
9. What is the difference between a codon and an anticodon?
A codon is a three-nucleotide sequence found on the messenger RNA (mRNA) molecule that specifies a particular amino acid or a stop signal. An anticodon is a corresponding three-nucleotide sequence found on a transfer RNA (tRNA) molecule. During translation, the anticodon on the tRNA carrying an amino acid binds to the complementary codon on the mRNA, ensuring the correct amino acid is added to the polypeptide chain. For example, if the mRNA codon is AUG, the corresponding tRNA anticodon would be UAC.
10. What is the role of the wobble hypothesis in explaining the degeneracy of the code?
The wobble hypothesis, proposed by Francis Crick, helps explain how multiple codons can code for a single amino acid. It states that while the first two bases of a codon-anticodon pairing must be precise and follow standard base-pairing rules, the pairing at the third position of the codon (the 'wobble' position) can be less strict. This flexibility allows a single tRNA anticodon to recognise and bind to multiple different codons that code for the same amino acid, making the translation process more efficient and robust.










